3.1 Génesis y evolución del proyecto
En el año 2018, algunos estudiantes de grado estaban interesados en desarrollar un trabajo de fin de grado en el ámbito del deep learning y contactaron con el director de mi tesis. Su interés se centraba en la temática de la visión artificial aplicada a la lengua de signos. Durante aquel período, tanto la visión artificial como la lengua de signos eran temas prominentes, y la fusión de técnicas vanguardistas de inteligencia artificial con la aplicabilidad social de asistir a un colectivo en desventaja resultaba (y sigue resultando) altamente atractiva. Dada nuestra familiaridad con la complejidad del problema, los estudiantes fueron redirigidos a un problema similar pero más acotado: el reconocimiento de SignoEscritura usando aprendizaje profundo. Esto culminó en un trabajo de fin de grado (Sánchez Jiménez, López Prieto, y Garrido Montoya 2019), dando inicio a la investigación en el objetivo previamente identificado: mejorar el tratamiento computacional de la SignoEscritura.
Al tratarse de un trabajo de fin de grado, el tiempo disponible para resolver el problema era limitado, y los estudiantes enfrentaban múltiples desafíos nuevos, como la lengua de signos, la visión artificial, y el trabajo en Linux, entre otros. A pesar de estos obstáculos, el trabajo fue crucial para identificar los principales problemas a superar en esta tarea.
Posteriormente, en el año 2019, Indra y Fundación Universia, con financiación del Banco Santander, anunciaron la IV Convocatoria de ayudas a proyectos de investigación en Tecnologías Accesibles, una convocatoria competitiva a nivel nacional. Ese año, como novedad, se permitió que los estudiantes presentaran propuestas, lo que me llevó a enviar la mía: “Visualizando la SignoEscritura” (VisSE), ver el logo en la figura 3.1 y el signo propio del proyecto en la figura 3.2. El objetivo era resolver el problema del uso de la SignoEscritura en el mundo digital, y tuve la suerte de ser seleccionado como ganador de la convocatoria1.
El plan previo del proyecto, enviado a la comunidad científica para su discusión en el Noveno Taller sobre la Representación y Procesado de Lenguas de Signos puede ser consultado en el capítulo 5. La pandemia de Covid-19 impidió la presentación presencial de la comunicación, pero gracias a los organizadores fue posible realizarla durante el siguiente congreso, en 2022, presentando además los resultados ya obtenidos. El póster presentado se puede encontrar también en las aportaciones del apéndice A.
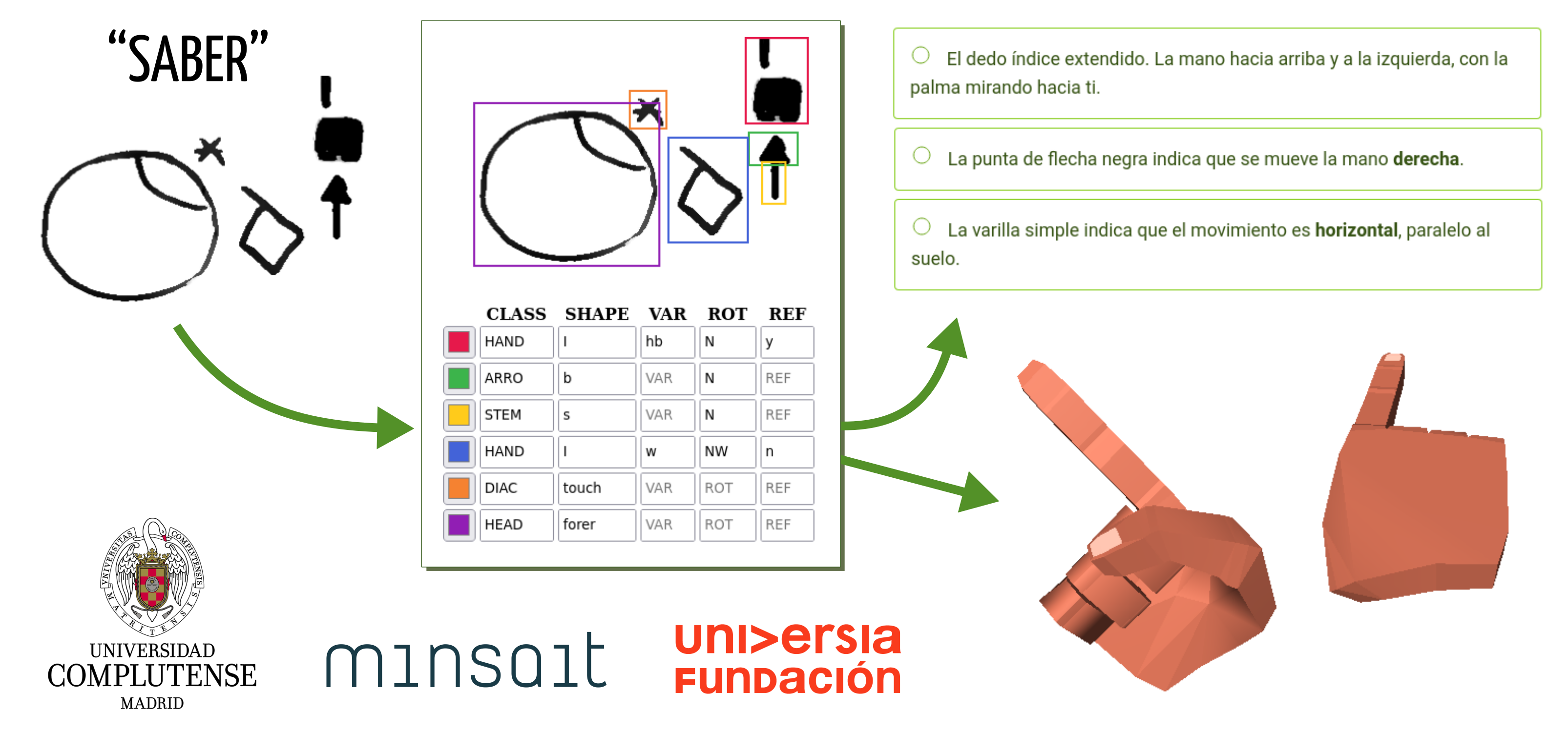
El objetivo de VisSE fue desarrollar la infraestructura y algoritmos para abordar el problema que nos ocupa, brindando además una utilidad final para los usuarios en forma de aplicaciones basadas en SignoEscritura. Aunque inicialmente el proyecto era quizá demasiado ambicioso, lo que llevó a reducir el alcance de las aplicaciones finales, los objetivos se alcanzaron, y la investigación básica se completó exitosamente, permitiendo futuros desarrollos.
Una parte complicada del proyecto fue la gestión económica y administrativa. Dado que era estudiante, no personal permanente de la universidad, y primerizo como investigador principal, los trámites burocráticos y la gestión fueron lentos y complejos. Además, la pandemia en 2020 causó un retraso casi de un año en el inicio del proyecto y dificultó el trabajo en persona y los contactos con asociaciones e investigadores. A pesar de ello, se logró llevar a cabo el trabajo, y los resultados se han convertido en el núcleo de esta tesis. A continuación, se presenta una descripción más detallada del desarrollo del proyecto enlazando a los diferentes resultados publicados. En la figura 3.3 se puede observar un esquema de alto nivel de las distintas partes.